Seeq addresses the challenges of continuous and batch process manufacturing analytics by leveraging data science and data management innovations.
All Seeq capabilities are accessible via a REST API for industry-specific templates and third-party products.
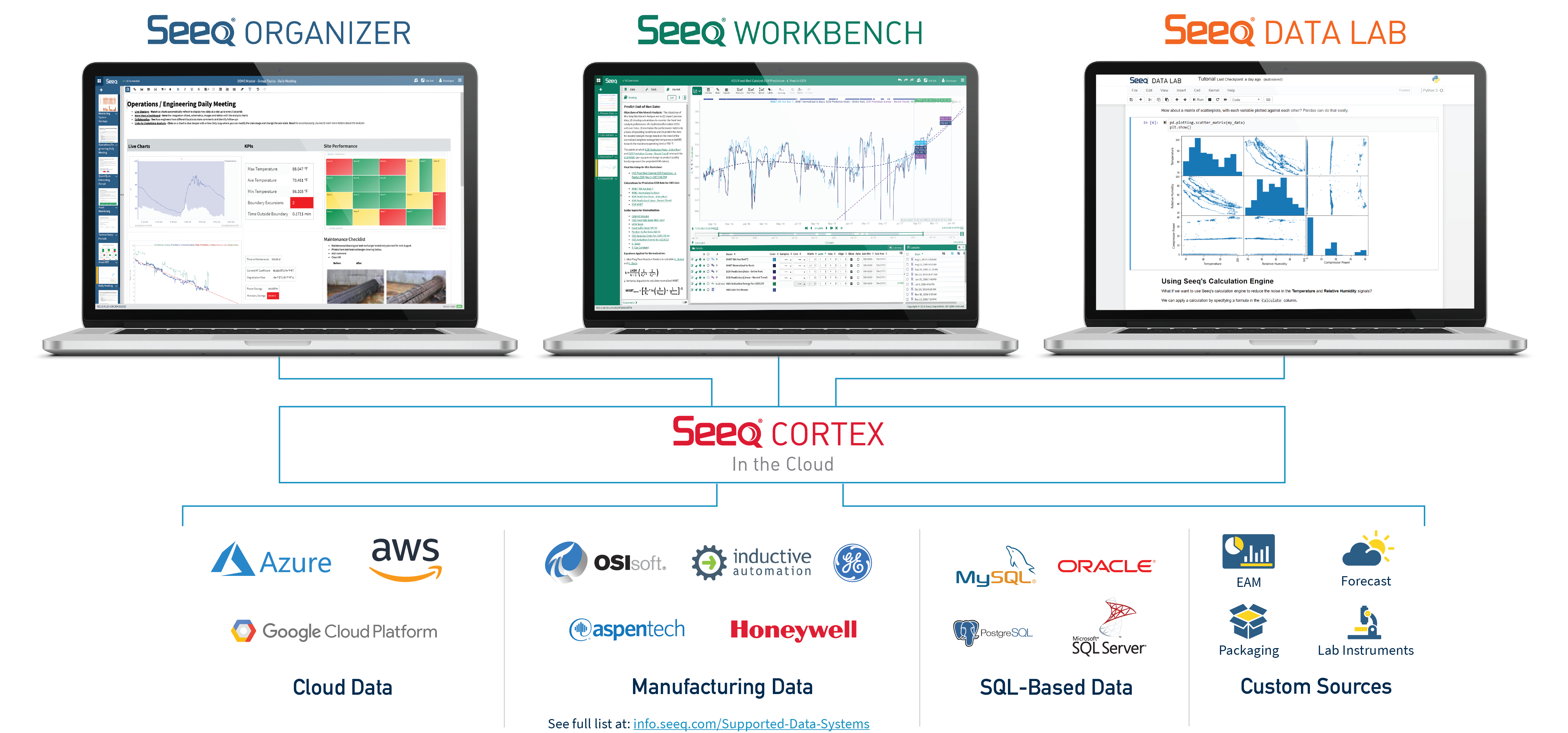
Seeq Workbench™
Seeq Workbench is a browser-based application for investigation and insight from process data. Seeq Workbench enables discovery and visualization of time series data, knowledge capture, and easy to use tool panels for common analytics functions like searching within signals, data cleansing, boundary definitions, and predictive analytics.
Seeq Organizer
Seeq Organizer is a browser-based application to assemble analyses and visualizations into reports, presentations, and meeting agendas as well as read-only web documents. Organizer Topics are dynamic because they tie directly to the underlying data, and are “time relative” so they can be defined by any batch, shift, day, etc.
Seeq Data Lab
Seeq Data Lab is built on Jupyter Notebooks and a Seeq Python library, called SPy, to enable process engineers to expand their Seeq analytics with Python machine learning, graphics, and scheduling libraries, and data scientists to access Seeq functionality for data connectivity, cleansing, modeling, and other Seeq features.
Seeq Cortex
Seeq Cortex is the application backend for Seeq Workbench, Organizer and Data Lab and runs best – for support, user experience, and pricing – as a SaaS (Software as a Service) application on Amazon Web Services (AWS) or Microsoft Azure. Seeq Cortex is also the center of Seeq’s IT support for data, security, user administration, and other features.
Extensibility
Users can customize Seeq Workbench with “Add-ons” to access custom tools, display panes and functions plus Seeq supports access to Python libraries in Data Lab. All Seeq functionality is accessible through a REST API with SDKs for C#, Python, MatLab, and Java, and data export options include Excel, PowerPoint, and any OData client (Tableau, PowerBI, etc.).
Connect data historians, sources, and silos
No matter where your data is or how it’s stored - on premise or in the cloud, in a historian or a SQL database, in data silos or a data lake - Seeq connects to it without duplicating or moving the data. This includes the ability to integrate data from production and business systems. For more information please visit our data connector page.
Deployment
Seeq runs best – for support, user experience, and pricing – as a SaaS (Software as a Service) application on Amazon Web Services (AWS) or Microsoft Azure and can be set up and running in hours. Connected data sources may be on premises, in the cloud, or a hybrid of both along with support for contextual (SQL) and ad hoc (CSV) data types.